Oxfordi kutatók kereszt-chatbot tényellenőrzést fejlesztettek ki a hallucinációk megállítására
Oxfordi kutatók kereszt-chatbot tényellenőrzést fejlesztettek ki a hallucinációk megállítására
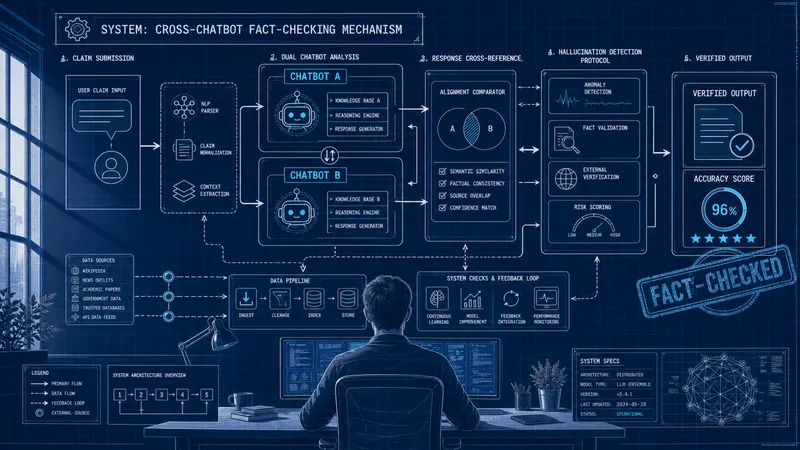
Az Oxfordi Egyetem kutatói egy ígéretes, új módszert dolgoztak ki a mesterséges intelligencia egyik legégetőbb problémája, a hallucinációk visszaszorítására. A technológia alapja egyfajta keresztellenőrzési folyamat, amely során több különböző chatbotot és nyelvi modellt kérnek fel ugyanazon állítások ellenőrzésére. A kutatók elképzelése szerint az AI-modellek közötti ellentmondások elemzésével hatékonyabban kiszűrhetők a téves vagy kitalált információk, mielőtt azok eljutnának a végfelhasználókhoz. Ez az eljárás alapjaiban változtathatja meg azt, ahogyan a chatbotok megbízhatóságát kezeljük, hiszen az eddigi manuális ellenőrzés helyett egy automatizált, belső kontrollmechanizmust vezet be a rendszerbe.
A hallucináció jelensége jelenleg komoly akadályt gördít az AI széles körű üzleti és tudományos alkalmazása elé, hiszen a Large Language Model (LLM) alapú rendszerek sokszor magabiztosan tálalnak valótlan adatokat igazságként. Az Oxfordi kutatócsoport megközelítése azért bír kiemelt jelentőséggel, mert a szemantikai konzisztenciára épít. Ahelyett, hogy egyetlen modelltől várnánk a tökéletes választ, több független forrásból származó kimenetet hasonlítanak össze. Ha több különböző chatbot – például egy GPT-alapú és egy Anthropic által fejlesztett modell – ugyanarra a komplex kérdésre gyökeresen eltérő választ ad, az egyértelmű jelzést küld a rendszernek, hogy az információ bizonytalan és alaposabb vizsgálatot igényel. Ezzel a módszerrel matematikai valószínűségek alapján mérhetővé válik, hogy egy adott válasz mennyire tekinthető stabil tudásnak vagy csupán statisztikai véletlennek.
Bár az újítás elméletben rendkívül hatékony lehet, a szakma egy része továbbra is szkeptikus a megoldással kapcsolatban. Egyes kritikusok szerint az eljárás leginkább ahhoz hasonlítható, mintha „tűzzel próbálnánk tüzet oltani”. A fő aggály az, hogy ha több olyan modell végzi az egymás közötti tényellenőrzést, amelyek hasonló adathalmazokon tanultak, fennáll a veszélye, hogy ugyanazokat a hibákat követik el, vagy megerősítik egymás tévhitét. Ha a chatbotok ugyanazokat az előítéleteket vagy téves forrásokat használják fel a válaszadáshoz, akkor a keresztellenőrzés során is egyetérthetnek a hamis információban, ami hamis biztonságérzetet adhat a fejlesztőknek és a felhasználóknak egyaránt.
A kritikák ellenére az Oxfordi kutatók bíznak abban, hogy a többoldalú validálás közelebb visz minket a valóban megbízható AI-rendszerekhez. A fejlesztés rávilágít arra, hogy a mesterséges intelligencia fejlődésének következő szakasza már nem csak a modellek méretének növeléséről, hanem azok önellenőrző képességének javításáról fog szólni. Ha sikerül finomítani az algoritmusokon, a módszer drasztikusan csökkentheti a téves információk terjedését az olyan kritikus területeken, mint az orvosbiológia, a pénzügyi elemzés vagy a jogi tanácsadás. Végső soron a cél egy olyan stabil ökoszisztéma kialakítása, ahol a különböző AI-ágensek képesek objektív kontrollt gyakorolni egymás felett, minimalizálva az emberi beavatkozás szükségességét a rutinszerű tényellenőrzési folyamatokban.